
Automated Processes and DSP in Python
Here are before and after screenshots of our dialog loudness charts (zoomed in for readability) showing all of the files for one language in our game. These are now part of our new dialog post-processing pipeline. File names have been changed for illustration purposes. With modern desktop browsers, hovering the mouse over the charts will dynamically show loudness values. Click on the charts if you’d like to load the actual interactive chart in a new tab. The loudness values are calculated with a slightly modified version of the ITU BS.1770-4 algorithm.


Several AES (Audio Engineering Society) papers have discussed adjusting this algorithm for different purposes. Our use is a bit of a misuse in that this algorithm was never designed for the shorter, bite-sized chunks of dialog often in games, but rather longer audio program material like movie mixes. We have a lot of ideas on how to modify the algorithm to make it better suited for our needs. I’m glad we can springboard off of 1770 going forwards.
Here’s another before and after of our worst case.


You can see the dialog is more uniform now. Before post-processing, the dialog swings wildly between -31 LUFS and -12 LUFS. We can get the dialog even tighter, but in my testing, it starts to sound unnatural. Remember, the algorithm is not meant for this type of short-form measurement, and a manual balancing pass has already been roughed-in during the dialog design stage. Hence, there’s a human judgment call already baked in we’re trying to retain. This is a post-process adjustment. Does it pass the listening test? Well, it’s better than without it, but it’s not as solid as someone with good, experienced ears mastering the dialog manually. We can see if training a neural network to do the classification will improve the results, and for that, we’d need to have a large, uniform training set that’s better than what the LUFS algorithm provides.
It used to take 20 hours to process a set of 5000 files. After some optimization, it now takes around 45 minutes. Multithreading/multiprocessing would be the next obvious upgrades. The entire process revolves around this push-pull concept where it rocks back and forth between loudness LUFS targets and peak audio limits until it gets within a specified tolerance. It’s my version of a machine learning gradient descent algorithm except once it hits “good enough” it bails. I also force it to quit after a specified number of tries since sometimes we get bad audio input. All internal audio processing is done in 64-bit floats.
Here are a few screenshots of the audio limiter module in this pipeline as I was prototyping it. It’s an offline, lookahead, brickwall, peak limiter designed to work in the context of our project’s dialog needs.
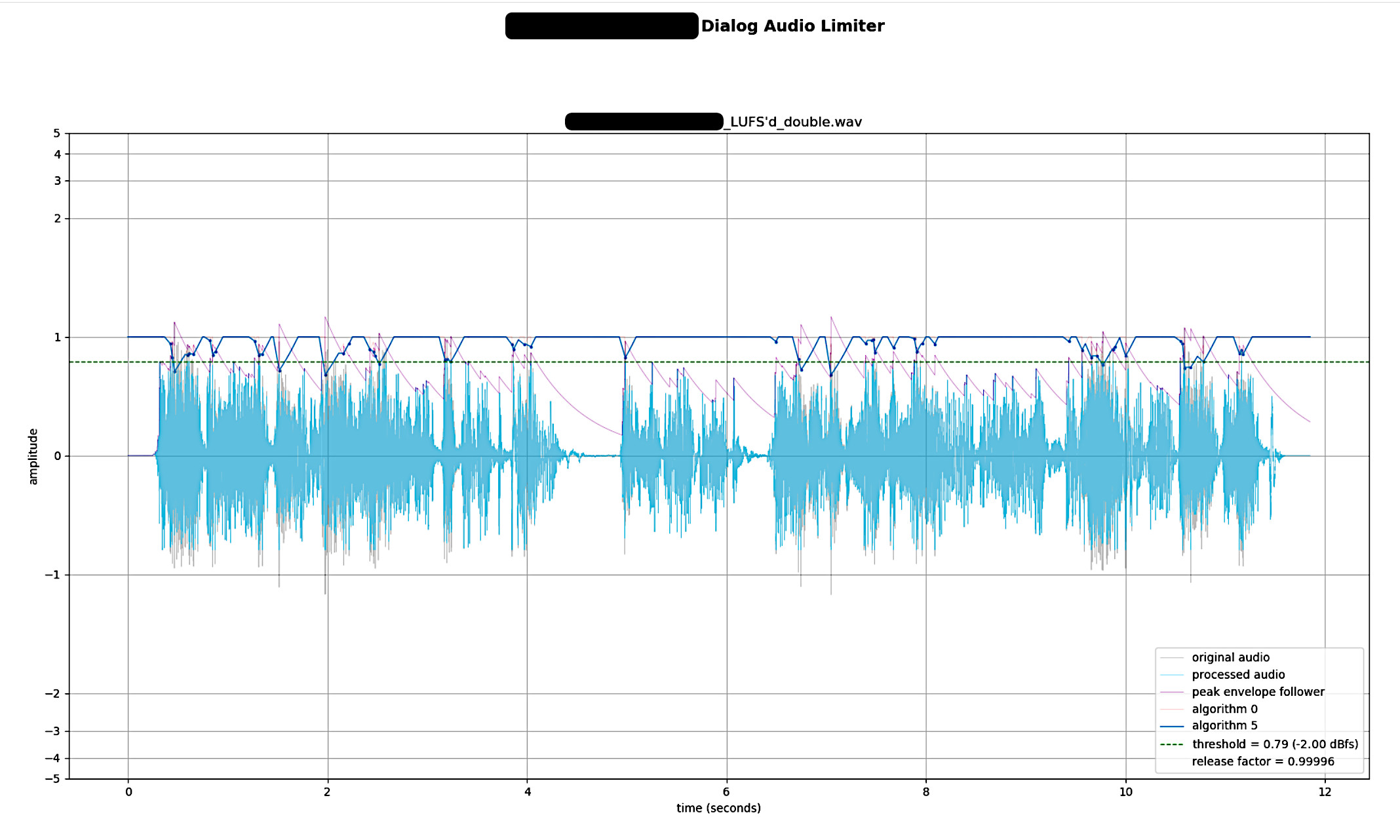
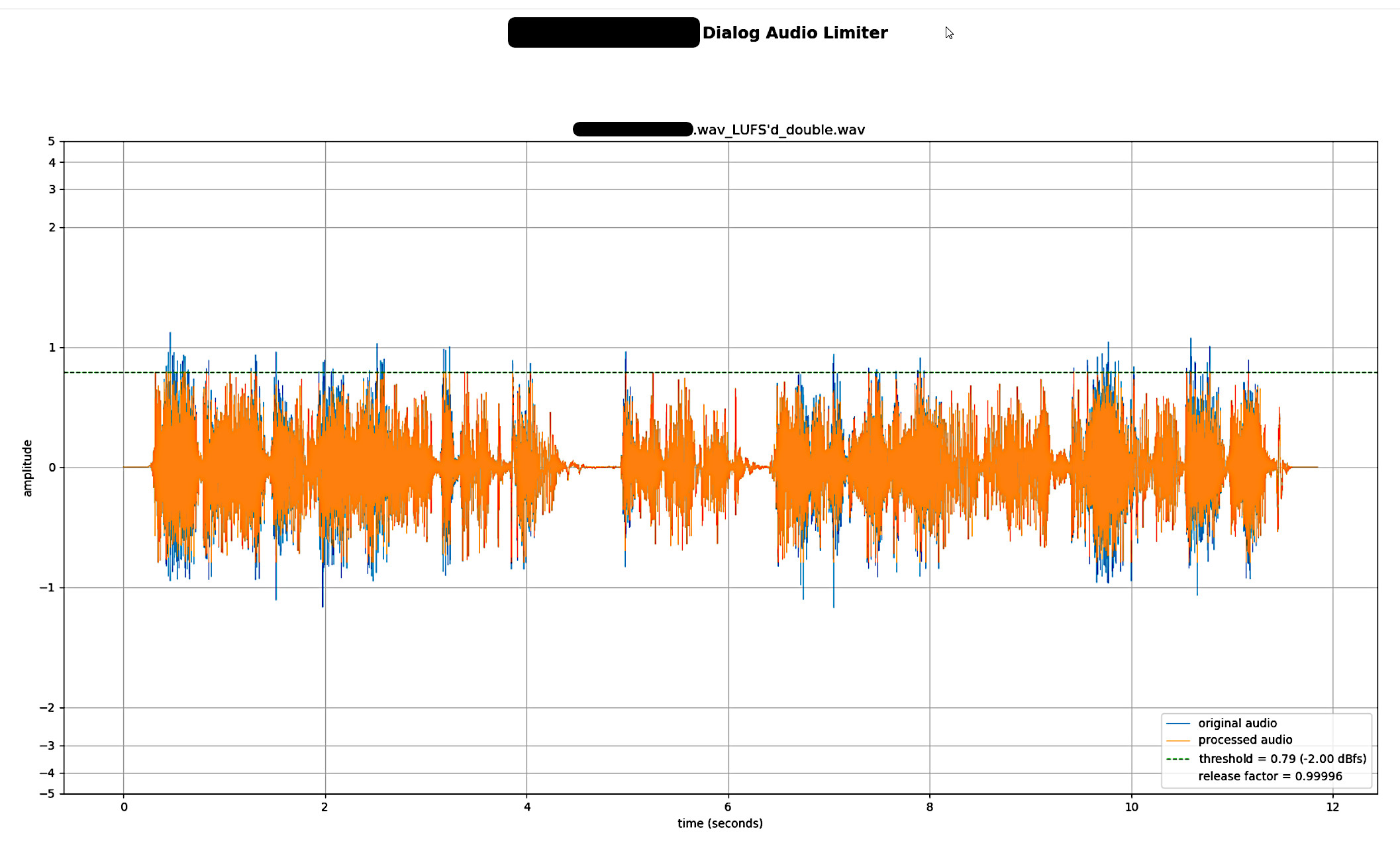
The pipeline tool does a lot quality assurance checks and reporting as well. It tests for spelling mistakes, bit depth, channel count, audio codec, audio container, sampling rate, missing files, and so on. We have a particular project need in that a parallel set of differently-processed dialog is used to animate faces. It’s a requirement that these files match their counterpart in length down to the frame (sample). The tool flags any discrepancies but can also fix these automatically.
I developed everything in Python 3 using the standard libraries that are popular in data science and AI these days, namely NumPy and Matplotlib. Other Python libraries that were a big help: SoundFile, SoundCard, pyloudnorm, PeakUtils, Pygal, and openpyxl. No external tools or libraries outside of the Python ecosphere are used. No dependencies on 3rd-party or proprietary commercial VST audio plugins, hosts, or DAWs. Easy to add to Jenkins and any game build pipeline.
What I shared here is just the tail end of a complete game dialog pipeline. Finding the right balance of removing the tedium while maintaining creative flexibitilty is more up front work but with exponential gains later. Ultimate creative flexibility usually means a lot of manual and proprietary techniques and devices that can be tedious to repeat across a dozen languages. Complete automation usually means being creative but within a constrained paradigm defined by the tools and process. Many automated dialog processing chains I see are in series with one audio plug-in chained after another. But on StarCraft II, much of our dialog effects required parallel audio processing that had to combine at the end:
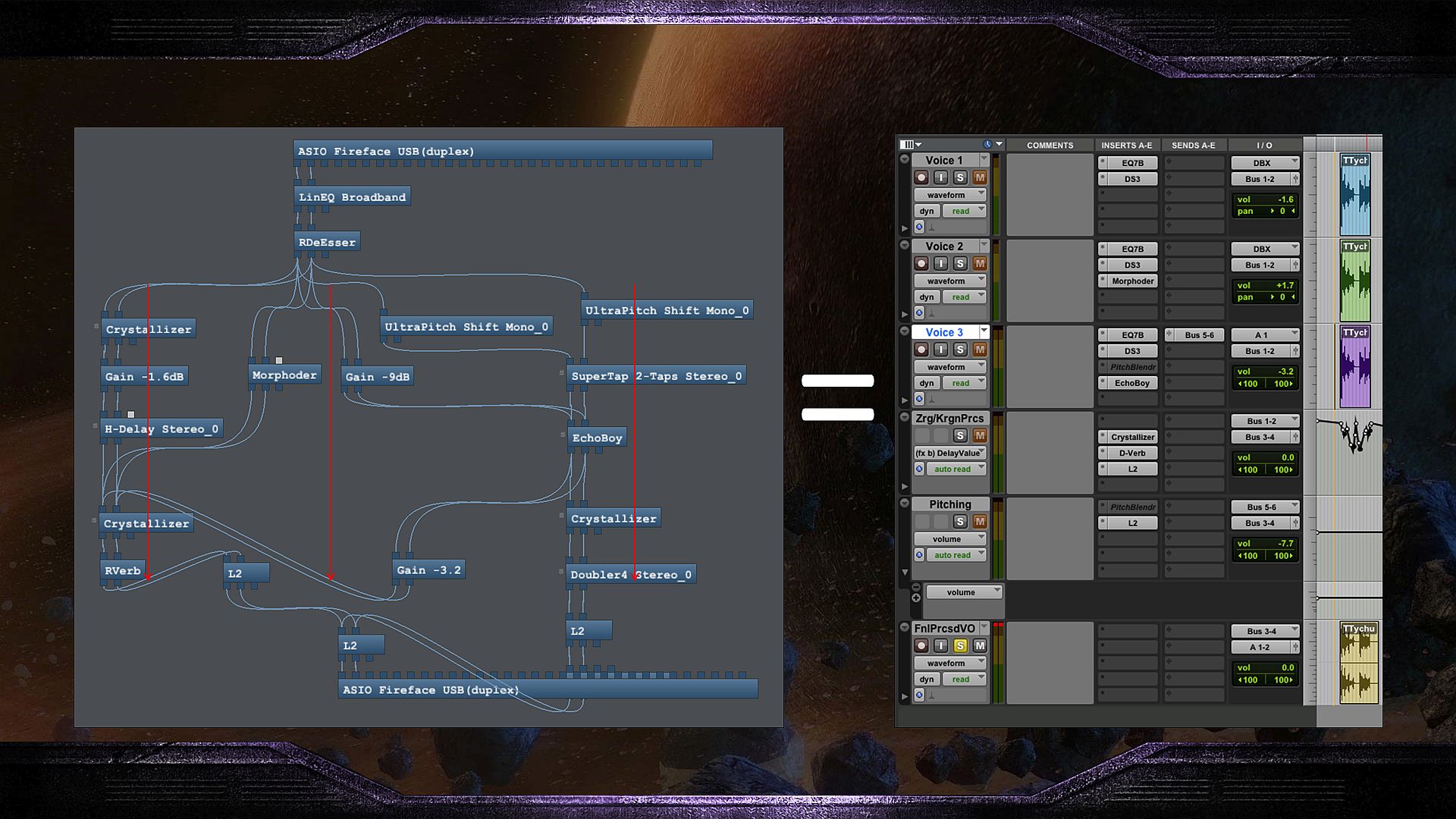
Other dialog lines required sound effects to be edited and mixed around the context of the sentence and adjusted for different locales. Some used different sound effects with dynamic length dependencies as a modulation source for the dialog. We also had quad dialog files. Sometimes we had a particular recipe of typically offline audio processess, like reverse, process, edit, reverse, and reprocess. We designed techniques and scripts to automate much of this stuff, while regularly reminding ourselves about tempering all of the automation with artistry. It became a well-balanced hybrid approach. We relied on SoX, Bidule, Reaper, Sound Forge, WaveLab, and scripting, and I think there are even more options now. All in all, it still takes a dialog professional with good ears, sensibilities, and craft to evaluate the results, improve the process, design new processes, and handle the unavoidable special cases.